对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
写在前面
- 准备考试,整理ceph 相关笔记
- 内容涉及:Blue Store OSD 存储引擎介绍,对应 OSD 的不同创建方式
- 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
BlueStore 简介
从 Ceph 12.2.0(Luminous) 版本开始的。在 Luminous 版本中,BlueStore 被引入作为一种新的、高性能的 OSD 存储引擎,以替代旧的 FileStore 引擎。
在 Ceph 中,BlueStore 可以提供更快的响应时间和更高的数据吞吐量,同时也具有更好的可靠性和稳定性。相比之下,旧的 FileStore 存储引擎通常需要更多的 CPU 和内存资源,对 IO 延迟的敏感度也较高。
FileStore 将对象存储为块设备基础上的文件系统(通常是 XFS)中的文件。
BlueStore 将对象直接存储在原始块设备上,免除了对文件系统层的需要,提高了读写操作速度,通过直接操作底层块设备来管理数据,而不是传统的文件系统。
这种方法提供了更好的性能和可靠性,因为可以将数据划分为较小的块并使用校验和来检测错误。此外,BlueStore可以直接与Solid State Drive(SSD)交互,并利用其快速读写速度。
BlueStore还具有可扩展性,可以处理数百万个物理盘和千亿个对象。它实现了动态负载平衡和自动恢复机制,以确保高可用性和数据可靠性。
BlueStore 架构
Ceph 集群中存储的对象有下面三部分构成:
BlueStore 将 对象 元数据 存储在 块数据库 中,块数据库将元数据作为键值对存储在 RocksDB 数据库中,这是一种高性能的键值存储,块数据库驻留于存储设备上的一个小型 BlueFS 分区,BlueFS 是一种最小的文件系统,设计用于保存 RocksDB 文件,BlueStore 利用预写式日志 (WAL)以原子式将数据写入到块设备。预写式日志执行日志记录功能,并记录所有事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| +-------------------------------------------------------+
| |
| Application / User Process |
| |
+-----------+-------------------------------------------+
| (RADOS Client API)
+-----------+-------------------------------------------+
| |
| RADOS |
| |
+-----------+-------------------------------------------+
| |
+-----------v------+ +-----------------------+
| | Write | |
| OSD Daemon +---------->+Wal |
| | | |
+-----------^------+ +-----------------------+
| |
| |
+-----------v------+ +-----------------------+
| | | |
| BlueFS +---------> | Bluestore data|
| | | |
+-----------^------+ +-----------------------+
| |
+-----------v------+ |
| | +-----------------------+ |
| RocksDB +---------> | SSD/NVMe device | |
| | | | |
+-----------^------+ +-----------------------+ |
| |
| |
+-----------v------+ +-----------------------+ |
| | | | |
| Block +---------> | Rotating disk | |
| Device | | | |
| | +-----------------------+ |
+------------------+ |
|
Hardware (Storage Nodes) |
|
+------------------+ |
| | +-----------------------+ |
| Network +---------> | | |
| | | CPU / RAM | |
+------------------+ | | |
+-----------------------+
|
预写式日志(Write-Ahead-Log,简称 WAL): 是一种常见的数据库和文件系统技术,用于提高数据持久性和可靠性。
WAL 的基本思想是在执行实际的数据更改操作之前,先将数据更改操作写入一个专门的日志文件中,然后再将其应用到存储中。
通过这种方式,WAL 可以确保对数据的操作被记录下来,即使在出现故障或崩溃的情况下也可以进行恢复。
在 Ceph 中,WAL 被广泛应用于 OSD 上的处理操作中。每个 OSD 都有一个特殊的预写式日志设备(WAL device),用于记录 OSD 写入的所有数据更改操作。通过使用 WAL,Ceph 可以在发生故障或崩溃时快速恢复数据,并确保数据的可靠性和一致性。
BlueStore 性能
FileStore 先写入到日志,然后从日志中写入到块设备。
BlueStore 可避免这种双重写入的性能损失,直接将数据写入块设备,同时使用单独的数据流将事务记录到预写式日志。
当工作负载相似 时,BlueStore 的写操作速度约为 FileStore 的 两倍,如果在集群中混用不同的存储设备,您可以自定义BlueStore OSD来提入性能。
创建新的 BlueStore OSD 时,默认为将数据、块数据库和预写式日志都放置到同一个块设备上。从数据中分离块数据库和预写式日志,并将它们放入更快速的 SSD 或 NVMe 设备,或许能提高性能。
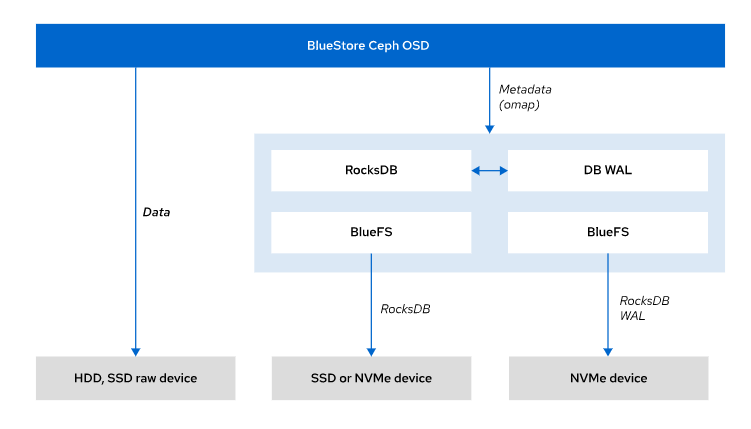
例如,如果对象数据位于 HDD 设备上,可以通过将块数据库放在 SSD 设备上并将预写式日志放到 NVMe 设备上来提高性能
使用服务规范文件定义 BlueStore 数据、块数据库和预写日志设备的 位置。示例如下:
指定 OSD 服务对应的 BlueStore 设备
1
2
3
4
5
6
7
8
9
10
11
12
13
| service_type: osd
service_id: osd_example
placement:
host_pattern: '*'
data_devices:
paths:
- /dev/vda
db_devices:
paths:
- /dev/nvme0
wal_devices:
paths:
- /dev/nvme1
|
BlueStore 存储后端提供下列功能:
- 允许将不同的设备用于数据、块数据库和预写式日志 (WAL)
- 支持以虚拟方式使用 HDD、SSD 和 NVMe 设备的任意组合
- 通过提高元数据效率,可以消除对存储设备的双重写入
BlueStore 在用户空间内运行,管理自己的缓存,并且其内存占用比 FileStore 少,BlueStore 使用 RocksDB 存储键值元数据,BlueStore默认是自调优,但如果需要,可以手动调优BlueStore参数
BlueStore 分区写数据的块大小为 bluestore_ min_alloc_size 参数的大小,缺省值为4kib .
bluestore_min_alloc_size 参数指定了每个对象分配所需的最小空间量,即使对象实际大小较小也会分配该数量的空间。如果要写入的数据小于该大小,则 BlueStore 将剩余空间用0填充。- 设置较小的
bluestore_min_alloc_size 可能会导致过多的碎片和浪费,因为一些较小的对象在分配时仍然需要使用与较大对象相同的空间。但是,如果设置较大的 bluestore_min_alloc_size ,则可能会浪费更多的空间,因为对象可能只使用其中的一部分空间。
bluestore_min_alloc_size 参数应根据特定的工作负载和性能需求进行调整。对于需要存储许多小型对象的应用程序,可能需要将此值设置得较小,而对于需要存储大型对象的应用程序,可能需要将此值设置得较大。
BlueStore 数据库分片
BlueStore 可以限制存储在 RocksDB 中的大型 map 对象的大小,并将它们分布到多个列族中,这个过程被称为分片。
使用 sharding(分片) 时,将访问修改频率相近的密钥分组,以提高性能和节省磁盘空间。Sharding 可以缓解RocksDB压缩的影响,压缩数据库之前,RocksDB 需要达到一定的已用空间,这会影响 OSD 性能,这些操作与已用空间级别无关,可以更精确地进行压缩,并将对 OSD 性能的影响降到最低
Red Hat建议配置的 RocksDB 空间至少为数据设备大小的 4%
在Red Hat Ceph Storage 5 (ceph version 16)中,默认启用分片,从早期版本迁移过来的集群的 osd 中没有启用分片,从以前版本迁移过来的集群中的osd将不会启用分片
使用 ceph config get 验证一个 OSD 是否启用了 sharding ,并查看当前的定义
1
2
3
| [ceph: root@clienta /]
config get osd.1 bluestore_rocksdb_cf
true
|
为 true 的时候说明默认启用了分片
osd 分片的参数定义
1
2
3
| [ceph: root@clienta /]
config get osd.1 bluestore_rocksdb_cfs
m(3) p(3,0-12) O(3,0-13)=block_cache={type=binned_lru} L P
|
block_cache={type=binned_lru}: 这是 RocksDB 的缓存设置。这里使用了 binned LRU 策略作为块缓存的替换策略。
L: 这是 BlueStore 的 日志设置,表示将日志写入硬盘而不是内存。这对数据持久性非常重要,因为任何未同步的写操作都会在下次启动时丢失。
P: 这是 BlueStore 的 预分配设置。预分配是一种优化技术,可以在写入新对象时事先分配足够的磁盘空间,以减少写入延迟和碎片。此处,“P”表示预分配已启用。
m(3) p(3,0-12) O(3,0-13):在这个映射中
- m(3) 表示使用 mon0、mon1 和 mon2 作为监视器。
- p(3,0-12) 表示
数据池中有 13 个 PG,它们被分配到了 OSD 0 到 OSD 12 上
- O(3,0-13) 表示
对象池中也有 13 个 PG,它们被分配到了 OSD 0 到 OSD 13 上
数据池(Data Pools):数据池用于存储客户端的数据。例如,如果您想在Ceph中创建一个文件系统或块设备,就必须将其存储在数据池中。数据池通常会经过复制或编码以提高容错性和可靠性。
对象池(Object Pools):对象池用于存储Ceph内部使用的对象,如 PG Map、OSD Map、Mon Map等。这些对象也可以被视为元数据,因为它们包含了关于Ceph集群的配置信息和状态信息。与数据池不同,对象池通常不需要复制或编码,因为它们已经具有容错性和可靠性。
在大多数 Ceph 用例中,默认值会带来良好的性能。生产集群的最佳分片定义取决于几个因素,Red Hat建议使用默认值,除非面临显著的性能问题。
在生产升级的集群中,可能需要权衡在大型环境中为 RocksDB 启用分片所带来的性能优势和维护工作
可以使用 BlueStore 管理工具 ceph-bluestore-tool 重新共享 RocksDB 数据库,而无需重新配置 osd 。要重新共享一个 OSD,需要停止守护进程并使用 --sharding 选项传递新的 sharding 定义。--path 选项表示 OSD 数据 Location,默认为/var/lib/ceph/$fsid/osd.$ID/
1
2
3
| [ceph: root@node /]
--path <data path> \
--sharding="m{3) p{3,0-12) 0(3,0-13)= block_cache={type=binned_lru} L P" reshard
|
提供 BlueStore OSD
作为存储管理员,可以使用 Ceph Orchestrator 服务在集群中添加或删除osd,添加OSD时,需要满足以下条件:
- 设备不能有分区
- 设备不能被挂载
- 设备空间要求5GB以上
- 设备不能包含
Ceph BlueStore OSD
使用 ceph orch device ls 命令列出集群中主机中的设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| [ceph: root@clienta /]
Hostname Path Type Serial Size Health Ident Fault Available
clienta.lab.example.com /dev/vdb hdd 18238 10.7G Unknown N/A N/A Yes
clienta.lab.example.com /dev/vdc hdd 23948 10.7G Unknown N/A N/A Yes
clienta.lab.example.com /dev/vdd hdd 6910 10.7G Unknown N/A N/A Yes
clienta.lab.example.com /dev/vde hdd 6673 10.7G Unknown N/A N/A Yes
clienta.lab.example.com /dev/vdf hdd 24354 10.7G Unknown N/A N/A Yes
serverc.lab.example.com /dev/vde hdd 23095 10.7G Unknown N/A N/A Yes
serverc.lab.example.com /dev/vdf hdd 2285 10.7G Unknown N/A N/A Yes
serverc.lab.example.com /dev/vdb hdd 4690 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdc hdd 1257 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdd hdd 26214 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vde hdd 10957 10.7G Unknown N/A N/A Yes
serverd.lab.example.com /dev/vdf hdd 12634 10.7G Unknown N/A N/A Yes
serverd.lab.example.com /dev/vdb hdd 24357 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdc hdd 3194 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdd hdd 13989 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vde hdd 28908 10.7G Unknown N/A N/A Yes
servere.lab.example.com /dev/vdf hdd 22042 10.7G Unknown N/A N/A Yes
servere.lab.example.com /dev/vdb hdd 27870 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdc hdd 25566 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdd hdd 8868 10.7G Unknown N/A N/A No
[ceph: root@clienta /]
|
Available 列中标签为 Yes 的节点为 OSD 发放的候选节点。如果需要查看已使用的存储设备,请使用 ceph device ls命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [ceph: root@clienta /]
DEVICE HOST:DEV DAEMONS WEAR LIFE EXPECTANCY
1257 serverc.lab.example.com:vdc osd.1
13989 serverd.lab.example.com:vdd osd.7
18237 serverc.lab.example.com:vda mon.serverc.lab.example.com
24357 serverd.lab.example.com:vdb osd.3
25566 servere.lab.example.com:vdc osd.6
26214 serverc.lab.example.com:vdd osd.2
27870 servere.lab.example.com:vdb osd.4
31796 clienta.lab.example.com:vda mon.clienta
3194 serverd.lab.example.com:vdc osd.5
4690 serverc.lab.example.com:vdb osd.0
5497 servere.lab.example.com:vda mon.servere
8868 servere.lab.example.com:vdd osd.8
9172 serverd.lab.example.com:vda mon.serverd
[ceph: root@clienta /]
|
使用 ceph orch device zap 命令准备设备,该命令 删除所有分区并清除设备中的数据 ,以便将其用于资源配置,使用 --force 选项确保删除上一个OSD可能创建的任何分区
1
2
| [ceph: root@node /]
device zap node /dev/vda --force
|
BlueStore OSD 配置方法
基于Orchestrator提供
Orchestrator 服务可以发现集群主机之间的可用设备,添加设备,并创建 OSD守护进程。Orchestrator 处理在主机之间平衡的新 osd 的放置,以及处理 BlueStore 设备选择
使用 ceph orch apply osd --all-available-devices 命令提供所有可用的、未使用的设备
1
2
3
4
| [ceph: root@node /]
orch apply osd --all-available-devices
[ceph: root@clienta /]
Scheduled osd.all-available-devices update...
|
该命令创建一个OSD服务,名为osd.all-available-devices,使 Orchestrator 服务能够管理所有OSD供应。Orchestrator从集群中的新磁盘设备和使用ceph orch设备zap命令准备的现有设备自动创建osd
可以看到上面的候选节点自动创建了 OSD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| [ceph: root@clienta /]
Hostname Path Type Serial Size Health Ident Fault Available
clienta.lab.example.com /dev/vdb hdd 18238 10.7G Unknown N/A N/A No
clienta.lab.example.com /dev/vdc hdd 23948 10.7G Unknown N/A N/A No
clienta.lab.example.com /dev/vdd hdd 6910 10.7G Unknown N/A N/A No
clienta.lab.example.com /dev/vde hdd 6673 10.7G Unknown N/A N/A No
clienta.lab.example.com /dev/vdf hdd 24354 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdb hdd 4690 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdc hdd 1257 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdd hdd 26214 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vde hdd 23095 10.7G Unknown N/A N/A No
serverc.lab.example.com /dev/vdf hdd 2285 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdb hdd 24357 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdc hdd 3194 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdd hdd 13989 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vde hdd 10957 10.7G Unknown N/A N/A No
serverd.lab.example.com /dev/vdf hdd 12634 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdb hdd 27870 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdc hdd 25566 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdd hdd 8868 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vde hdd 28908 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdf hdd 22042 10.7G Unknown N/A N/A No
[ceph: root@clienta /]
|
若要禁用 Orchestrator 自动供应 osd,请将非托管标志设置为 true
1
2
| [ceph: root@node /]
orch apply osd --all-available-devices --unmanaged=true
|
基于指定目标提供
可以使用特定的设备和主机创建OSD进程,使用 ceph orch daemon add 命令创建带有指定主机和存储设备的单个OSD守护进程
停止 OSD 进程,使用带OSD ID的 ceph orch daemon stop 命令
使用 ceph orch daemon rm 命令移除OSD守护进程
释放一个OSD ID,使用 ceph osd rm 命令
基于服务规范文件提供
使用服务规范文件描述OSD服务的集群布局,可以使用过滤器自定义服务发放,通过过滤器,可以在不知道具体硬件架构的情况下配置OSD服务,这种方法在自动化集群引导和维护窗口时很有用
下面是一个示例服务规范YAML文件,它定义了两个OSD服务,每个服务使用不同的过滤器来放置和BlueStore设备位置
1
2
3
4
5
6
7
8
9
10
11
| service_type: osd
service_id: osd_size_and_model
placement:
host_pattern: '*'
data_devices:
size: '100G:'
db_devices:
model: My-Disk
wal_devices:
size: '10G:20G'
unmanaged: true
|
osd_size_and_model 服务指定任何主机都可以用于放置,并且该服务将由存储管理员管理,数据设备必须有一个100gb或更多的设备,提前写日志必须有一个10 - 20gb的设备。数据库设备必须是My-Disk型号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ---
service_type: osd
service_id: osd_host_and_path
placement:
host_pattern: 'node[6-10]'
data_devices:
paths:
- /dev/sdb
db_devices:
paths:
- /dev/sdc
wal_devices:
paths:
- /dev/sdd
encrypted: true
|
osd_host_and_path 服务指定目标主机必须在node6和node10之间的节点上提供,并且服务将由协调器服务管理,数据、数据库和预写日志的设备路径必须 /dev/sdb、 /dev/sdc 和 /dev/sdd,此服务中的设备将被加密
执行ceph orch apply命令应用服务规范
其他OSD实用工具
ceph-volume 命令是将逻辑卷部署为 osd 的模块化工具,它在框架类型中使用了插件,ceph-volume 实用程序支持 lvm 插件和原始物理磁盘,它还可以管理由遗留的 ceph-disk 实用程序提供的设备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| [ceph: root@serverc /]
====== osd.0 =======
[block] /dev/ceph-096c573c-d9b8-4fd6-acf9-a4a33d1352ae/osd-block-82c98821-3c02-468a-8e2f-7c5dfc2a0fbe
block device /dev/ceph-096c573c-d9b8-4fd6-acf9-a4a33d1352ae/osd-block-82c98821-3c02-468a-8e2f-7c5dfc2a0fbe
block uuid dL5z54-f0sG-gHjB-4277-EjVW-w80o-x0LKeE
cephx lockbox secret
cluster fsid 4c759c0c-d869-11ed-bfcb-52540000fa0c
cluster name ceph
crush device class None
encrypted 0
osd fsid 82c98821-3c02-468a-8e2f-7c5dfc2a0fbe
osd id 0
osdspec affinity None
type block
vdo 0
devices /dev/vdb
====== osd.1 =======
[block] /dev/ceph-1171e241-a952-4e41-938a-45354c55f27d/osd-block-1ca3352b-4c2d-4a85-86cc-33d1715c1915
block device /dev/ceph-1171e241-a952-4e41-938a-45354c55f27d/osd-block-1ca3352b-4c2d-4a85-86cc-33d1715c1915
block uuid AzAAag-oKMq-RQl1-7lZO-4ez0-iMsC-F0bDm3
cephx lockbox secret
cluster fsid 4c759c0c-d869-11ed-bfcb-52540000fa0c
cluster name ceph
crush device class None
encrypted 0
osd fsid 1ca3352b-4c2d-4a85-86cc-33d1715c1915
osd id 1
osdspec affinity None
type block
vdo 0
devices /dev/vdc
....................
[ceph: root@serverc /]
|
使用ceph-volume lvm 命令手动创建和删除 BlueStore osd,在块存储设备 /dev/vdc 上创建一个新的BlueStore OSD:
1
2
| [ceph: root@node /]
lvm create --bluestore --data /dev/vdc
|
create 子命令的另一种选择是使用 ceph-volume lvm prepare 和 ceph-volume lvm activate 子命令,通过这种方法,osd逐渐引入到集群中,可以控制新的osd何时处于up或in状态,因此可以确保大量数据不会意外地在osd之间重新平衡
子命令用于配置OSD使用的逻辑卷,可以指定逻辑卷或设备名称,如果指定了设备名,则会自动创建一个逻辑卷
1
2
| [ceph: root@node /]
lvm prepare --bluestore --data /dev/vdc
|
activate子命令为OSD启用一个systemd单元,使其在启动时启动,使用activate子命令时,需要从命令ceph-volume lvm list的输出信息中获取OSD的fsid (UUID)。提供唯一标识符可以确保激活正确的OSD,因为OSD id可以重用
1
2
| [ceph: root@node /]
lvm activate <osd-fsid>
|
创建OSD后,使用systemctl start ceph-osd@$id命令启动OSD,使其在集群中处于up状态
batch子命令可以同时创建多个osd。
1
2
| [ceph: root@node /]
lvm batch --bluestore /dev/vdc /dev/vdd /dev/nvme0n1
|
inventory子命令用于查询节点上所有物理存储设备的信息
1
2
3
4
5
6
7
8
9
| [ceph: root@serverc /]
Device Path Size rotates available Model name
/dev/vde 10.00 GB True True
/dev/vdf 10.00 GB True True
/dev/vda 10.00 GB True False
/dev/vdb 10.00 GB True False
/dev/vdc 10.00 GB True False
/dev/vdd 10.00 GB True False
|
使用面板工具

Demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
ceph health
ceph df
ceph osd tree
ceph device ls
ceph orch device ls | grep server | grep Yes
ceph orch daemon add osd serverc.lab.example.com:/dev/vde
ceph orch daemon add osd serverc.lab.example.com:/dev/vdf
ceph orch ps | egrep 'osd.9|osd.10'
ceph df
ceph osd tree
ceph orch apply osd --all-available-devices
ceph orch ls | grep osd.all-available-devices
ceph osd tree
ceph orch daemon stop osd.11
ceph orch daemon rm osd.11 --force
ceph osd rm osd.11
ceph orch osd rm status
ceph orch device zap servere.lab.example.com /dev/vde --force
ceph orch device ls | grep servere.*vde | grep No
ceph device ls | grep servere.*vde
ceph orch ps | grep osd.11
ceph orch ls --service-type osd --format yaml | head -n 10 > all-available-devices.yaml
echo unmanaged: true >> all-available-devices.yaml
ceph orch apply -i all-available-devices.yaml
ceph orch ls | grep available | grep unmanaged
ceph orch daemon stop osd.15
ceph orch daemon rm osd.15 --force
ceph orch osd rm status
ceph osd rm osd.15
ceph orch device zap serverd.lab.example.com /dev/vdf --force
sleep 60
ceph orch device ls | grep serverd.*vdf | grep Yes
|
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 :)
https://docs.ceph.com/
https://access.redhat.com/documentation/zh-cn/red_hat_ceph_storage/5
https://github.com/ceph/ceph
CL260 授课老师课堂笔记
© 2018-至今 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)

